武大上交联手,大语言模型消除幻觉,双向自回归建功
这是来自于武汉大学和上海交通大学的合作研究 BatGPT,一个使用双向自回归架构对各种类型的输入(包括文本提示、图像和音频)生成自然流畅的文本回应的大规模语言模型。
- 技巧 1:在训练过程中反转序列。学习预测下一个 token 同时学习预测上一个 token。
- 技巧 2:来自非人类的强化学习。用模型的反馈训练 RL 模型。
- 技巧 3:将 RLHF 数据收集形式化为简单的配对比较。
然而比较有争议的是,这篇论文的题目缩写是“BAT”,这个组合似乎只在中国网友之间引起了共鸣。一些人甚至过度解读这个题目的缩写,他们热衷于将“Bat”翻译为“蝙蝠”,甚至部分人结合论文作者的所在院校和城市,由此引发了地域黑。
论文题目:
BatGPT: A Bidirectional Autoregessive Talker from Generative Pre-trained Transformer
论文链接:
https://arxiv.org/abs/2307.00360
论文速览
尽管目前的许多语言模型都取得了不错的进展,但现如今的许多模型仍然面临着一些限制和挑战:
- 一个突出的问题是“有限的记忆”效应,即随着序列长度的增加,模型维持上下文的能力减弱。
- 这些模型常常出现幻象,即生成与输入上下文不符的输出,并且在高效捕捉复杂依赖关系方面遇到困难。
本文的模型:
- 在建模层面,引入了一种双向自回归架构,传统的语言模型一般只从左到右生成文本,这可能导致固定记忆效应和模型产生虚构内容。而双向自回归架构允许模型不仅从左到右生成自回归文本,也可以从右到左进行生成,从而有效地减少了固定记忆效应,并缓解了模型的虚构问题。
- 在训练方面,BatGPT 采用的新颖参数扩展方法利用了在较小模型的预训练中获得的知识,从而显著减少了时间和计算成本。受到 RLHF 模型的启发,BatGPT 采用了来自 AI 和人类反馈的强化学习,旨在提高模型的对齐性能。
双向自回归预训练
BatGPT 是使用双向自回归语言建模目标进行预训练的,这是传统自回归目标的修改版本,模型通过学习基于先前看到的所有 token 和前向和后向上来预测下一个 token,使得模型能够捕捉到这两个方向上的依赖关系。给定序列 ,预训练的 BatGPT 输出从序列的两端获取的每个位置上可能 token 的分布:
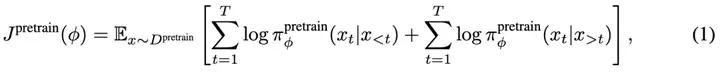
通过最大化这个分布,BatGPT 学习捕捉在其训练数据所囊括的广泛数据中内在的复杂的语言模式、语义和结构,从而产生更连贯和流畅的输出。
指导微调
在预训练阶段之后,BatGPT 通过指导微调进一步提升性能。这个过程利用了大量的带有提示的数据,以〈提示,回答〉对的形式存在。这些对作为上下文提示让模型能够生成合适的回答,从而使 BatGPT 的行为与人类的指令和期望相一致。具体来说,带提示的数据集被表示为 ,包含了一系列序列 ,其中 代表提示, 代表相应的回答。指导微调的目标是优化以下似然函数:
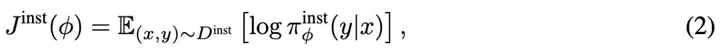
此外,BatGPT 还通过多轮对话数据进行进一步的微调,这种数据将多轮对话历史串联起来作为输入,将最后一轮的回答作为输出。这种训练策略专门设计用来增强 BatGPT 在理解和保持长对话线程方面的能力。它优化了 BatGPT 在长对话中保存对话上下文的能力,使对话更连贯和有意义。指导微调阶段实质上是调整 BatGPT 的参数,使其能够更好地生成与给定提示一致的回答,从而使 BatGPT 能够有效处理和适当回答不同的指令。
从人类反馈中强化学习
为了使对齐过程更加高效和灵活,BatGPT 不仅从人类反馈中学习,还从其他人工智能系统生成的反馈中学习。RLHF 的基本目标是优化奖励模型 (其根据收集到的偏好数据进行训练的),然后使用Proximal Policy Optimization(PPO)来训练 BatGPT。
人类偏好数据收集
为了通过强化学习训练 BatGPT,需要收集大量基于人类判断的偏好数据。作者开发了一个偏好数据注释平台,如图 1 所示是呈现给标注员的前端页面设计。注释员在前端页面上被呈现两个模型输出,分别标记为 A 和 B,以对同一个指令回复。这些输出可以都来自 BatGPT,也可以来自 BatGPT 和另一个 LLM。
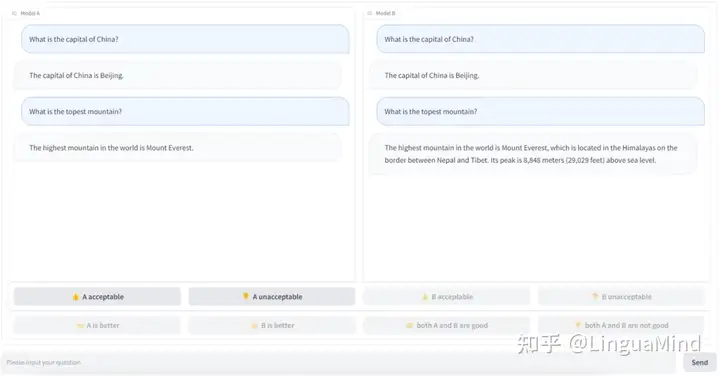
为了评估输出的可接受性,尤其关注潜在的有害性,以及衡量输出的有用性,使用这些预定义选项简化了评估模型输出的过程,减少了歧义,并增加了收集反馈的可靠性,从而确保对 BatGPT 的训练过程更加稳健和有效。
BatGPT 从人类和 AI 收集到的反馈进行整合,创建了一个广泛的偏好数据集,进一步增加了训练池的深度和多样性。
RLHF 训练
BatGPT 使用了奖励模型 来预测每个 ,, 三元组在偏好数据集中的奖励 和 ,其中 ,。奖励模型通过最小化如下损失进行训练:
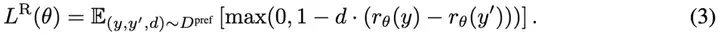
一旦奖励模型训练完成,它将通过 Proximal Policy Optimization (PPO) 更新策略参数 。为了保持预训练和指导微调阶段所获得的能力,相应的损失项被纳入到目标函数中,得到一个扩展的目标函数。 通过最大化以下目标进行训练:
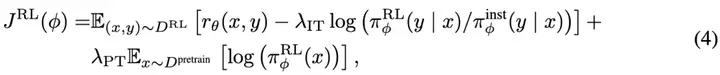
从而使强化学习策略与指导微调和预训练分布保持接近。这种混合强化学习方法使得 BatGPT 能够充分利用人类的细致理解和 AI 系统的稳健一致性。因此,BatGPT 能够生成更有益、更符合要求、更安全的输出,适用于各种应用场景。
实验结果
如表 1 所示,在所有面向中文的语言模型中,BatGPT 排名第二,展现出令人期待的性能。总体而言,BatGPT 在各种主题上表现出鲁棒的性能,以及处理不同类型的提示的能力,展示了其广泛的功能和适用于各种应用领域的能力。
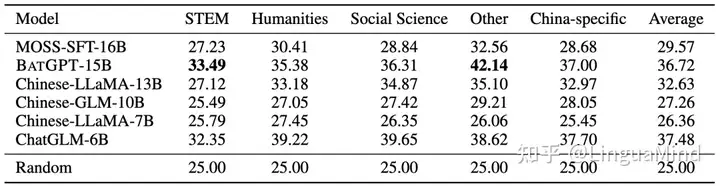
但也许是因为国内大模型相关的研究还不够充分,中文基准的评估结果的可信度不那么高,有国外网友评价[1]这项研究:作者并没有在已知的基准上进行衡量,而是在中文基准上进行评估。目前虽然处于领先地位,但可能很难估计这会意味着什么。
蝉鸣AI生产力-教你用AI卷别人(原AIGC知识星球) » 武大上交联手,大语言模型消除幻觉,双向自回归建功