LangChain + OpenAI 之提示工程
导语 | 如果说新的人工智能范式已经到来了,那么你需要掌握的一项重要技能就很可能是如何有效地与机器对话,或者也可以称之为「提示工程」。那是不是就大家网上收集一堆 prompt 然后看着用就好了,还是说这个事情还是有一定技术门槛并且能作为一个新的职业存在呢。。。
What is Prompt Engineering
从某种意义上讲,如果你使用 ChatGPT 或者与任何 LLM 进行对话,那么你就已经在做提示工程的事情了。当我们向 LLM 提问时,通常会提供它额外的信息,我们实际上是在提示 LLM 产生我们认为有用的下游答案。就像与另一个人谈事前交代背景,只不过换成了AI。简而言之,提示工程就是通过适当的文字提示方法来产生所需的 LLM 回答的方法论。
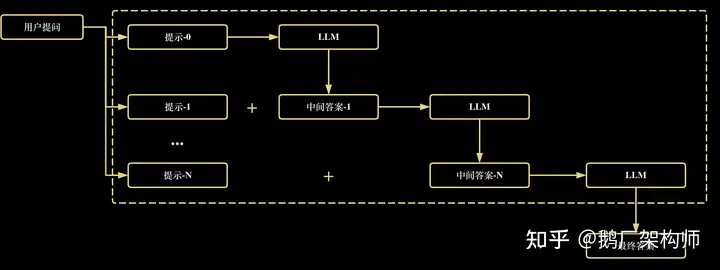
我们想让 AI 来帮我们完成一个任务,大体的交互过程可以归纳为下面这张图,首先用户提出一个问题比如介绍下什么是斐波那契数列,也许大模型直接回答不了或者回答不专业,这个时候我们需要给出一个提示(提示-0)比如角色扮演“你现在是一个数学老师”,然后它返回给你一个答案(中间答案-1),得到的答案并不一定符合预期,那么需要进一步优化提问(提示-1),可能会用到原来的提问信息以及当前给出的反馈。就这样不断迭代直到我们满意它输出的结果为止。提示工程师的意义就在于让整个中间过程(虚线框部分),通过程序来自动化从而简化使用体验,来满足不同程度的用户的使用需求。
这一套能够程序化的跑通需要下面两个关键的条件:
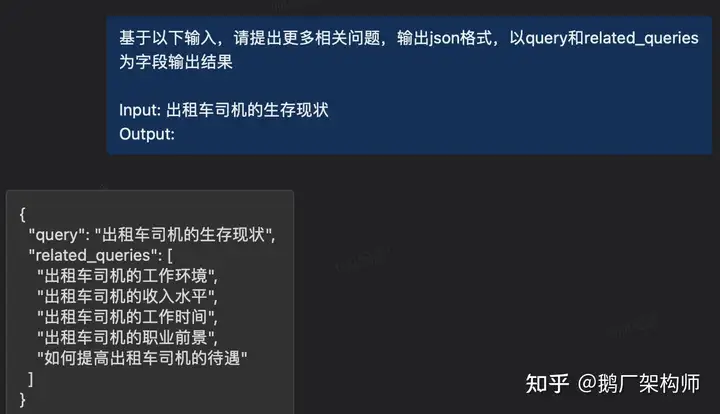
1)我们需要知道什么样的提示可以让 LLM 产生“可预期”的回答,这里的”可预期“主要是指输出我们想要的数据结构。说到底,它是一个语言模型,你输入一段字符串,它返回你另一段字符串。只有返回的字符串的结构符合一定规律,才能解析成特定结构的数据供下游程序来执行。从而整个流程能自动化起来。这一步很多大模型就做不到。我也没试过太多的大模型,或者没有探索出合适的指令不敢下定论,我试过的支持中文的模型中也就OpenAI 的 gpt 系列能比较稳定可靠的做到这一点。下面是一个需要它输出结构化数据的例子。
2)我们还需要有这样的一个预期,就是用户通常会向 LLM 提出什么样的问题,这个就和应用场景强相关了。不同使用场景下,用户的问题多种多样,比如是做客服还是解方程还是写文案都需要定制化的提示文案。
这么说还是太过抽象,下面是我自己yy的一个故事给大家分享下。主要是想说明至少在当下,这确实是可以成为一种职业存在的,不过要做好,门槛还挺高。
The story begins here …
如何通过提示工程,让 chatGPT 扮演多重角色,并根据用户输入自由切换。
The Wild Idea
一位高瞻远瞩的老板相信在不久的将来,人们会越来越依赖聊天机器人来解决日常的问题。于是他决定开始卖聊天机器人。可是现在市面上大语言模型这么多,套一层皮就是一个机器人,怎么做出差异化来呢。人们的问题千奇百怪,且往往需要用不同领域的专业知识来解决,他意识到如果能够让这个机器人成为各个领域的专家,那么这款产品必将获得成功。于是信心满满开始重金悬赏,他找到了你······
你开始调研这些大语言模型,不管是开源需要自己部署的还是付费调接口的,指令微调的还是人类反馈强化过的,他们都好比是一个“大学生”,什么都知道一些但了解的都不深,不过都有不错的学习能力。于是你开始思考:要机器人成为 N 个领域的专家,要么用 N 个领域的数据(假设能收集到这样的数据)对开源的模型进行消费级显卡下低成本的微调,生成 N 个垂类模型;要么挂载 N 个领域的知识库,回答问题前先在知识库里搜索查找相关资料,然后让这个大学生做阅读理解;还有一种最简单粗暴的做法就是回答问题前提示它你是 XX 领域的专家,hopefully,它能 act like a XX 领域的专家,那么要扮演 N 个专家就需要 N 套提示指令。不管哪一种方式,你都需要设计一个解决方案,在用户提问之后,系统能够准确判断,应该从这 N 个模型或者 N 个知识库亦或是 N 套角色扮演中选取哪个来产出答复。当然可以从产品形态上去解决,比如让用户看到的是 N 个不同的机器人,相当于你让用户自己做判断应该向谁提问。然而老板说,产品直觉告诉他我们必须让用户感受到这是一个全能的机器人,这会让我们的产品成为用户的首选。另外,更加现实的考量就是当 N 很大怎么办,用户不知道该怎么选择怎么办,用户都很懒,用户都很无知。可能 N >= 10 他们就会觉得脑壳疼,可能他们自己都区分不了他的问题是该问物理专家还是化学教授······
LangChain to the rescue
你说老板说的对,你再去想想。于是给出了下面这个设计方案,总要有一个环节做领域专家的判断,既然不让用户做,那就让大模型做。简单来说就是通过提示工程是可以让 LLM 扮演各种角色的,那么我们先让它扮演一个任务转发器(router),以期它能准确地判断转发给哪个专家,再让它扮演对应的专家来回答问题。于是你找到了 langchain 这个强大的库,45.3k 的 star 量看着就靠谱······
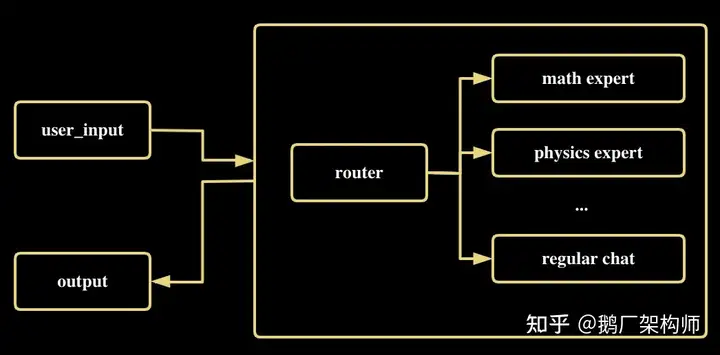
Prototyping
你扒了一段时间 Langchain 库的源码,终于领悟了它各种 Chain 的妙用。于是开始了尝试,用上面提到的最简单粗暴的做法(即直接告诉它应该扮演什么专家)来探索这个事情的可行性,首先把每个专家的提示词准备好。并准备一段描述在 description 中,来说明这个提示词的特点,以供后面转发器角色来判断应该把任务给谁。(文末附完整代码)
PHYSICS_TEMPL = """
你是一位非常聪明的物理教授。你善于用简明易懂的方式回答物理问题。当你不知道某个
问题的答案时,你会坦率承认自己不知道。
问题:
{input}
"""
MATH_TEMPL = """
你是一位非常优秀的数学家。你擅长回答数学问题。
你之所以能够做得这么好,是因为你能够将难题分解成组成部分,回答每个组成部分,
然后将它们组合起来回答更广泛的问题。
问题:
{input}
"""
prompts_info = [
{"name": "physics", "description": "擅长回答物理问题", "prompt_template": PHYSICS_TEMPL},
{"name": "math", "description": "擅长回答数学问题", "prompt_template": MATH_TEMPL},
]用准备好的领域专家提示词,和底座大模型(gpt-3.5)结合来构建每个领域专家的 chain。
llm = OpenAIChat()
candidate_chains = {}
for p_info in prompts_info:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
chain = LLMChain(llm=llm, prompt=prompt)
candidate_chains[name] = chain
default_chain = ConversationChain(llm=llm, output_key="text")以下是让它成为转发器的提示文,很直接,就是告诉它请从 candidates 中选出最合适的 prompt 来回答问题。需要它返回一个结构化的 JSON 数据,方便下游代码来解析,并且为了更好的回答你的问题,允许它做适当的修改。这里{candidates} 部分会填充备选的专家和相关的描述: candidates_str = "\n".join([f"{p['name']}: {p['description']}" for p in prompts_info])。
PROMPT_SELECT_TEMPL = """
针对输入到语言模型的原始文本,选择最适合该输入的模型提示。您将得到可用提示
的名称以及最适合该提示的描述。如果您认为修改原始输入将最终导致语言模型产生
更好的回答,则可以对其进行修改。
<< 格式 >>
返回一个Markdown代码片段,其中包含一个 JSON 对象的代码,格式如下:
```json
{{{{
"destination": string \\ 提示的名称或者 "DEFAULT"
"next_inputs": string \\ 原始的输入或者它可能的修改版本
}}}}
```
请注意: "destination" 必须是下面指定的候选提示名称之一,或者如果输入
不适合任何候选提示,则可以为 "DEFAULT"。请记住:"next_inputs" 如果您
认为不需要进行任何修改,可以直接使用原始输入。
<< 候选提示 >>
{candidates}
<< 输入 >>
{{input}}
<< 输出 >>
"""将填充后的提示文和底座大模型 llm 一起通过 LLMRouterChain 来实例化就可以完成转发器
# 构建提示选择的提示
candidates_str = "\n".join([f"{p['name']}: {p['description']}" for p in prompts_info])
prompt_select_template = PROMPT_SELECT_TEMPL.format(candidates=candidates_str)
# 解析输出结果
prompt = PromptTemplate(
template=prompt_select_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
router_chain = LLMRouterChain.from_llm(llm, prompt) Reflection
后来你发现,这一套逻辑也可以通过 agent + tool 的方式来实现。每一个领域专家的 chain 就是一个 tool,agent 就是转发器,让它 plan 出每一步 action 和 action_input。在完成这样的任务上没有大区别,agent 的好处可能是会对结果进行判断如果不好再试一次这样子。再后来,你发现这一切能 work 的关键,不仅需要底座大模型能对用户输入进行准确判断,还需要你能否写出合适的提示文,来让充当转发器的底座大模型能写出符合预期的结构化的数据,因为 RouterOutputParser 中完全是根据预期的模版再进行解析的。。。
Proof of Concept
一顿骚操作,代码写好了。第一个问题是关于”黑体辐射“,它尽然真的改写了你的问题,可能需要改一下 llm 的 temperature 不过这不重要,可能这个回答多少满足了用户需求。重要的是对于这么一个典型的物理问题它找对了专家。第二个问题虽然没有答错,但没有那么惊艳,确实没有人知道最大的质数是多少,因为可以证明不存在最大的质数,预期是它能指出这一点并给出这个证明啥的······

Brave the World
最后我在想一个事情,一个自媒体团队需要多少人?网上看到如果是包含了图文和视频,兼做知识付费和训练营的自媒体团队,包括图文、视频制作、运营、商务,每个模块需要2~3人才能正常转起来。具备这些业务背景的从业者们,也不需要很资深,如果有一个半桶水的程序员(只需要一个),知道怎么把 python 脚本跑起来,就能 cover 至少查资料、写图文文章、写视频文案、群里常规性的对接客户、回答群友学员提问的工作。也许不久的未来,各大招聘平台会出现会出现一批”技术文案“岗。
附完整代码
需要设置 `OPENAI_API_KEY` 环境变量,另外装包 `pip install langchain textwrap` 就可以跑了。Have Fun!
from langchain.llms import OpenAIChat
from langchain.chains import ConversationChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router import MultiPromptChain
import textwrap
import time
PROMPT_SELECT_TEMPL = """
针对输入到语言模型的原始文本,选择最适合该输入的模型提示。您将得到可用提示
的名称以及最适合该提示的描述。如果您认为修改原始输入将最终导致语言模型产生
更好的回答,则可以对其进行修改。
<< 格式 >>
返回一个Markdown代码片段,其中包含一个 JSON 对象的代码,格式如下:
```json
{{{{
"destination": string \\ 提示的名称或者 "DEFAULT"
"next_inputs": string \\ 原始的输入或者它可能的修改版本
}}}}
```
请注意: "destination" 必须是下面指定的候选提示名称之一,或者如果输入
不适合任何候选提示,则可以为 "DEFAULT"。请记住:"next_inputs" 如果您
认为不需要进行任何修改,可以直接使用原始输入。
<< 候选提示 >>
{candidates}
<< 输入 >>
{{input}}
<< 输出 >>
"""
PHYSICS_TEMPL = """
你是一位非常聪明的物理教授。你善于用简明易懂的方式回答物理问题。当你不知道某个
问题的答案时,你会坦率承认自己不知道。
问题:
{input}
"""
MATH_TEMPL = """
你是一位非常优秀的数学家。你擅长回答数学问题。
你之所以能够做得这么好,是因为你能够将难题分解成组成部分,回答每个组成部分,
然后将它们组合起来回答更广泛的问题。
问题:
{input}
"""
prompts_info = [
{"name": "physics", "description": "擅长回答物理问题", "prompt_template": PHYSICS_TEMPL},
{"name": "math", "description": "擅长回答数学问题", "prompt_template": MATH_TEMPL},
]
llm = OpenAIChat()
candidate_chains = {}
for p_info in prompts_info:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
chain = LLMChain(llm=llm, prompt=prompt)
candidate_chains[name] = chain
default_chain = ConversationChain(llm=llm, output_key="text")
# 构建提示选择的提示
candidates_str = "\n".join([f"{p['name']}: {p['description']}" for p in prompts_info])
prompt_select_template = PROMPT_SELECT_TEMPL.format(candidates=candidates_str)
# 解析输出结果
prompt = PromptTemplate(
template=prompt_select_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
router_chain = LLMRouterChain.from_llm(llm, prompt)
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=candidate_chains,
default_chain=default_chain,
verbose=True,
)
def output_response(response: str) -> None:
if not response:
exit(0)
for line in textwrap.wrap(response, width=60):
for word in line.split():
for char in word:
print(char, end="", flush=True)
time.sleep(0.1) # Add a delay of 0.1 seconds between each character
print(" ", end="", flush=True) # Add a space between each word
print() # Move to the next line after each line is printed
print("----------------------------------------------------------------")
while True:
try:
user_input = input("请输入您的问题:")
response = chain.run(user_input)
output_response(response)
except KeyboardInterrupt:
break欢迎点赞分享,搜索关注【鹅厂架构师】公众号,一起探索更多业界领先产品技术。
蝉鸣AI生产力-教你用AI卷别人(原AIGC知识星球) » LangChain + OpenAI 之提示工程